DONT MISS YOUR CHANCE TO EXCEL IN DATA LAKE ARCHITECTURE ASSIGNMENT! HIRE TUTOR OF EXPERTSMINDS.COM FOR PERFECTLY WRITTEN DATA LAKE ARCHITECTURE ASSIGNMENT SOLUTIONS!
ITEC874 Big Data Technologies - Macquarie University
In this assignment you will explore the management of big data using Data Lake technology.
Learning Outcome 1: Obtain a high level of technical competency in standard and advanced methods for big data technologies.
Learning Outcome 2: Understand the current status of and recognize future trends in big data technologies.
Learning Outcome 3: Develop a competency with emerging big data technologies, applications and tools.
WORK TOGETHER WITH EXPERTSMIND'S TUTOR TO ACHIEVE SUCCESS IN DATA LAKE ARCHITECTURE ASSIGNMENT!
Introduction
In this report, we will discuss the case study based on the data lake Components.A data lake is a place where all data is stored in structured and unstructured form. In the data repository data is stored as it is. Apart from data warehouses, a data lake is capable of accommodating raw data and storing information, a flat-file architecture is used in Data Lake.A specific identifier is allocated to each data component in a data lake, as well as a collection of enhanced metadata labels is marked.The data lake may be questioned for appropriate information if a company issue occurs, but that narrower collection of information can be analyzed to assist give an explanation. Data Lake is also related to the Hadoop. In that case, company's data is stacked into Hadoop platform, and then some tools are applied to the data like data mining and business analytics.
The main purpose of make Data Lake is to provide raw data to the scientists. Data Lake is used for to start of data engines such as big data, AWS, visualization. It has become simple to store heterogeneous data. Without the need to structure details such a Data Lake into an industry-wide schema?The standard of analyzes also improves with the rise in information quantity, information quality, and metadata.Data Lake provides agility for company. For the important decision or business profitable decision or weather forecasting AI is used.It create a competitive environment to for business purpose.
New data utilization demands and even use situations arise incredibly quickly in a modern vibrant company setting.When a requirement paper is ready to represent required modifications to data stores or schemes, consumers also frequently shifted on to a distinct or conflicting set of modifications to the schema.By comparison, a data lake's entire thesis is about being prepared of an unspecified use case.
ARE YOU LOOKING FOR RELIABLE DATA LAKE ARCHITECTURE ASSIGNMENT HELP SERVICES? EXPERTSMINDS.COM IS RIGHT CHOICE AS YOUR STUDY PARTNER!
Part 1
Data Ingestion components
a. You need to research and identify the different types of data (from structured to unstructured) and data ingest (e.g., batch, micro-batch, real-time), and briefly explain them.
(a) Data ingestion
Data ingestion is a processing of importing data for recent uses or storage devices in a database. It can fetch data from storage devices to real-time and batch processes. Data ingestion is a method through which data is transferred from one location to another location or sources where it will be saved and examined. Data may have come from different sources and different formats like CSV, RDBMS, S3 buckets, etc.
Data can invest in batch in real-time, and it is called lambda architecture. Data is imported at frequently planned periods while you ingest data in the group. When using batch processing to give extensive opinions of group data this strategy tries to balance the advantages of batch and real-time methods, while also using actual-time processing to give opinions of time-sensitive info/data.
Structured and unstructured data
Structured and unstructured data are totally different from each-others. Structured is easy way to search information by algorithms. Unstructured data are more likely human language which does not fit in relational database.
Example of structured data
• Date
• Phone number
• Credit/debit card number
• Social security number
• Customer names
• Products names and number
• Transaction information
Examples of unstructured data
• Text files
• Reports
• Email message
• Surveillance imagery
• Audio and video files
b. Identify the existing Big Data Technologies and Tools for ingesting big data, e.g., Hortonworks DataFlow.
(b)Big data technologies and tools
Data ingestion tools provide a frame work of data storage that allows collecting information and import, load, transfer, integrated from a large range of data source.
Data ingestion tools are used for data sources, validate each file, and dispatch data item to destination to an effective ingestion process.
Data ingestion in big data technologies and tools work is cost effective solution, rapid extraction delivery data, and handle large amount of data.
Apache kayka- it is powerful and easy tools to used and implement.
Apache NIFI- it provides a reliable system to process and network system and it supports a robust and scalable directed graph of data routing, transferring.
Wavefront- it is technology of analyzing high level optical wave and creates an image how lights the traveled in the eyes.
Data Organization components
a. You need to research and compare various techniques for organizing data, e.g., Directory Structure, Version Control and Database Management Systems.
(a)Data organization
Data organization, the techniques by which data items are classified and organized to form them more beneficial. This is mainly related to physical records by some IT professionals, while some kinds of data organization may also pertain to electronic records. Example: we are considering mark obtained by 10 student out of 50. There score are given below:
45, 25,20, 47, 48, 30, 35, 15, 28, 39
This form of data will create confusing if data is more than hundreds or thousands. Now data is in the table form
|
Serial number
|
Mark scored
|
|
1
|
45
|
|
2
|
25
|
|
3
|
20
|
|
4
|
47
|
|
5
|
48
|
|
6
|
30
|
|
7
|
35
|
|
8
|
15
|
|
9
|
28
|
|
10
|
39
|
This form of data description is not difficult to analyses the data.
For organization Data Various techniques are used:
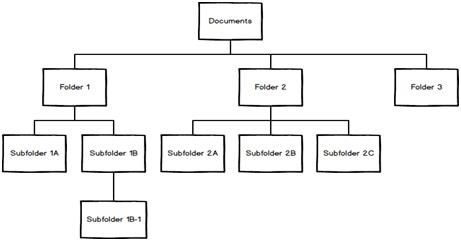
Directory Structure:
Directory Structure are a significant way of arranging, easy-to-manage and differentiated units to arrange your task documents.Generate a logical directory architecture to assist you to remain ordered, discover as well as collect your recorded documents readily, and execute this to save time of your task r project.
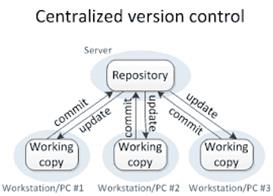
Version Control:
A version control structure is also an important way to manage the data. Version control promotes a proper way to the management of research data studies throughout a project where countless scientists are constantly redrafting and revising.
Revision control manages over time modifications to a set of information or data. It is possible to structure these modifications in different aspects. The information is often considered to be a compilation of many specific products, such as records or records, and modifications are monitored in individual records.
Database Management Systems:
A database is an associated data which shows the actual thing of the real world.DBMS is a software that stores and retrieves information from customers by taking suitable safety steps into consideration. It enables users to generate their own datasets according to their needs.

Hierarchical: This sort of DBMS uses the data storage link "parent-child."A hierarchical model is a data model where a tree-like design organizes the information. The information is collected as documents that are linked via connections with each other.
Comparison
|
Directory structure
|
Version control
|
Database management system
|
|
It is logical way of arranging and easy to maintain your task documents.
|
It manages the data in proper way and research data study through your projects.
|
It is software that stores and retrieve the data from the customers.
|
|
It discovers and collect data execute this save to time of your projects.
|
It provides all updates and commit to the users.
|
It represents the actual things of real world database.
|
b. Identify the existing Database Management Systems for each category, e.g. MySQL in Relational DBs and MongoDB in NoSQL document-oriented DBs.
(b) There is different type oftools and techniques of big data organization below:
Data analysis:Big data organization includes capturing data, data analysis, data storage, sharing, transfer and information privacy and resources. Big data organization consists with key concept- volume, velocity, and variety.
Hadoop:it is high quality availability object oriented platforms as known as hadoop. It is software that enables structured and unstructured data.
MongoDB: it is open sources database that is cross platform. MongoDB is stores the database in binary form and it is mainly used for scalable, obtainability and presentation.
Hive:it is database warehouse tools used in hadoop platforms. It can provide the same interface of SQL language.
SAVE YOUR HIGHER GRADE WITH ACQUIRING DATA LAKE ARCHITECTURE ASSIGNMENT HELP & QUALITY HOMEWORK WRITING SERVICES OF EXPERTSMINDS.COM
Data Security and Governance components
a. You need to research and identify the requirements for governing the right data access and the rights for defining and modifying data.
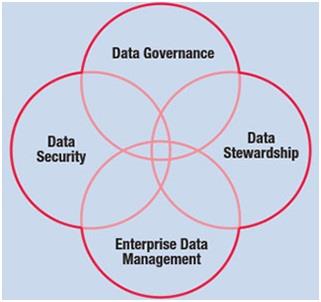
(a)Data security and governance
Data security is a secure process of data and the requirements of governing the right data access is permission that has been granted allow to human or computer software to locate and read digital information. Data security is still more crucial than ever is essential to have a powerful, up-to-date data management plan in place to keep your delicate details secure.
The most essential element of data governance is - data quality, security, master data management, data stewardship, and data architecture.
Data quality: Ensuring your data is of high quality and encapsulating data elements such as accessibility, relevance, and timeless.
Security, Privacy, and Compliance: Information on assets and categories can assist to decide the effect on your company if an asset is damaged.Hosting suppliers like Rackspace give security and access control solutions as portion of our Confidentiality and Data Protection service that helps handle sensitive information across your business.
Master Data Management: On to the word often misunderstood for being about data management. Although similar, MDM relates to data management procedures, norms, instruments, and policies. In essence, it interacts to data governance's organizational and strategic components and is a key element.
Data stewardship:it is term that describes person and their responsibility for establishing and maintaining data governance.
b. Identify the existing trust, security, and privacy issues in Big Data.
(b)Big data tools and technologies
Apache atlas: it is governance and framework for hadoop. It supports various hadoop to manage metadata in central repository.
Alation data catalog: it provides users single sources in reference of multiple data sources which helps finding data which users needed. It helps in automatically updating data dictionary and education users on governance for sharing information.
SAP master data governance:it is oriented data governance tools designed to support an organization to meet like data quality and data policy management.
Trust: big data sources for problem-solving should be made clear to business users. It requires the system for data determining and maintaining data accuracy and data flows.
Privacy: openness should be no system for personal collecting data that are kept secret. Persons should have the ability to correct information.
Security: security is creating and maintaining big data used in correct ways. The security is compulsory and necessary for both customer and computers.
Indexing and search components
a. You need to research on the topic "Federated Search" topic and identify technologies that facilitates the simultaneous search of multiple searchable resources.
(a) Federated Search
Federated search is a search engine enables users to search multiples files and webpages independents. Federated search is better to search one place to several. Google.com, amozon.com is another example of search engine which provide the related information of search. When searching a topic can you sure being able to do in single search page including database, Ethernet search engine, and electronic publication across different database sources and deleting duplicating.
Bielefeld academic search engine: this is multiple search engines, searches academic and related web resources.
Science.gov: it is provided by US agencies, this gateway allows over millions of web search pages of selected authorized science information. It consists of major search engine federated search and technology information.
Scienceaccelerator.gov:it access high quality publicly science search and technology collections organized under subject.
Worldwidescience.org: The search allows users to limit a search to a particular database. Development and maintained by the office international and technical information on behalf of worldwidescience.org. It provides a quick result of the federated search of national and international scientific database worldwide.
b. Identify the existing Big Data Technologies and Tools for indexing and searching the big data: e.g., Elasticsearch and some research outcomes.
(b)Indexing and Search
Big data technology is a search engine and there are some open source and big search engine that know how to search data. It needs to be able to search by unstructured and structured data and many running query.
Lucene: it is the techniques based on search algorithms under the apache licenses and high performance and scalable indexing.
Apache solr:it is enterprise server built in java under apache licenses. Apache solr can run full text search server, dynamic clustering and real-time indexing.
Elasticsearch: it is open source search engine built in apache solr and it is schema less multiple indexing.
DO YOU WANT TO EXCEL IN DATA LAKE ARCHITECTURE ASSIGNMENT? HIRE TRUSTED TUTORS FROM EXPERTSMINDS AND ACHIEVE SUCCESS!
Analytics components
a. You need to research and compare the techniques for analysing the data (from structured to unstructured) and extracting insight from them.
(a)Analytics data
Data analysis focus on planning approach to taking raw and planning data, mining data that are relevant the business goals, and drilling down into information to transform, facts ,matric. Implementing a Data analysis Suite in your organization it's more than just gathering extra information is about transforming this information into actionable ideas.
Techniques
NodeXL:nodeXL is open source for data analysis and visualization software. It supports data imports, graph visualization, graph analysis and data representation.
Wolfram Alpha: it is data analytic tools which used for computational knowledge engine founded by wolfram. In wolfram alpha, you get a quick answer to a factual query directly by computing the answer from external sources.
Google search operators: it is the most useful resource which helps to fast filtering of Google results.
Dataiku DSS: it is search resources that provide an interactive visual where they can create, update, and use like SQL language. It can help your development and operation by handling workflow automation and modifying data.
Comparison
|
NodeXL
|
Wolfram Alpha
|
Google search operators
|
Dataiku DSS
|
|
This technique can import several type of graph.
|
It provides technical research and computational knowledge engines
|
It helps you fast filter of Google results and discover new information.
|
It provides interactive interface and they can build and click or use SQL language.
|
|
It integrated into Microsoft excel 2007. 2010, 2013
|
It is add on 'apple siri'
|
It can work in all platforms.
|
It integrated into SPARK
|
b. Identify the existing Big Data Technologies and Tools for analysing the big data: SAS Tools (such as SAS Text-Analytics), Microsoft ML platform, Amazon ML Platform, and Apache Mahoot.
(b)There are different tools for analyzing the big data. Some of them are listed below:
SAAS Tools:
The SAS System is a module of software applications constructed to access, analyze and report data for a variety of. SAS statistical routines promote everything from sales forecasting to pharmacological assessment purposes. The SAS language involves a software package for analyzing and planning information for the assessment using SAS processes. SAS involves a range of parts to access databases and simple, improperly formatted files, manipulate information, and generate graphical output for web pages and other locations to be publishedto psychological/educational testing to business risk analysis. SAS is one of the leading educational research and data collection analytics platforms in universities, businesses, and organizations around the globe.
Apache Mahout:
Apache Mahout is a directory of scalable algorithms for machine learning, introduced on the upper edge of Apache Hadoop and using the Map Reduce paradigm. Machine learning is an artificial intelligence skill that relies on allowing computers to learn without specific programming and is widely used to enhance future performance based on earlier results. When big data is stored on the Hadoop Distributed File System (HDFS), Mahout offers data science instruments to discover significant patterns in the big data sets automatically. The objective of the Apache Mahout project is to create converting big data into large details easier and quicker.
R- Programming:
For statistical computing and graphics, it is free software computing system and software environment. The R language is commonly used in the development of statistical software and data analysis among information miners. In the latest years, ease of use and extensibility have significantly increased R's popularity.
Rapid Miner:
Rapid Miner works via visual programming and can modify, evaluate and design data. With an open-source platform for information preparation, machine learning, and model implementation, Rapid Miner makes data science teams more productive. Its integrated data science platform speeds up the construction of full analytical workflows in a single setting, from information preparation to machine learning to model validation to deployment, drastically enhancing effectiveness and reducing time to value for data science projects.
Pentaho:
Pentaho discusses the obstacles blocking the capacity of your organization to gain value from all of your information. The platform optimizes the preparation and mixing of any information and contains a range of instruments for easy analysis, visualization, exploration, reporting, and prediction. Open, embedded and expandable, Pentaho is designed to guarantee that every member of your team - from designers to company consumers - can readily convert information into value.
NEVER LOSE YOUR CHANCE TO EXCEL IN DATA LAKE ARCHITECTURE ASSIGNMENT - HIRE BEST QUALITY TUTOR FOR ASSIGNMENT HELP!
Data visualization Component
a. You need to research and identify the techniques for visualizing the data.
(a) Data visualization
There are different techniques for visualizing the data some of them are listed below:
Charts:the simple way to represent and development of one or more data set is called charts. It is very from bar and line charts relationship between overtime and pie charts.
Plots:it allow distributing two or more 2 dimensional or 3 dimensional data sets space to represent relationship between these data sets and parameters on the plots. It consists two most traditional are bubble plots and scatter. The big data analytics use box plots which is enable to visualize relationship between volumes of data.
Maps:A map is navigation of data or information and widely used in different industry. It allows to position element on object and area- geographical, creating plan, and website layout.
Diagram and matrices: diagram is usually used to complex data relationship and link includes various types of data in visualization.
Matrices is technique that allow to reflects relationship between multiple continue updating data sets.
b. Identify the existing Big Data Technologies and Tools for visualizing the big data: e.g. SAS10 Visual Analytics. Other examples include D3.JS and VIS.JS.
(b)There are different tools for visualizing the data some of them are listed below:
QlikView
QlikView is a product of Qlik, a Radnor, Pennsylvania, USA based software business. QlikView is one of the quickest increasing data visualization and business intelligence tools that are simple to communicate with. It offers Composable Search to uncomplicate decision-making. It's Composable Expertise allows you to concentrate, whenever and wherever you need, on the most appropriate information. It offers real-time cooperation with colleagues and associates, a relative data analysis, allows you to integrate your relevant information into a single app, and ensures that the organization's correct individuals have access to the information through its secure safety characteristics.
Tibco Spotfire
Tibco Spotfire is a business intelligence and analytics platform that provides you a fast overview of your information. It's accessible in editions for Desktop, Cloud, and Platform. It has a recommendation engine powered by AI that drastically reduces the time of information discovery. Data Wrangling's characteristic enables you identify information outliers, inconsistencies, and deficiencies rapidly. FIFA used the software during the 2010 World Cup to provide spectators with analytics on past performances by country teams. Users of spotfire are Procter and Gamble, Cisco, NetApp, Shell.
Watson Analytics
Watson Analytics is the cloud-based analytics service provided by IBM that allows you to find insights into your information rapidly. When you submit your information to Watson Analytics, it will demonstrate you the questions you can answer and then provide you with instantly-based information visualizations. You can also investigate your information through the processing of natural language. Other main characteristics include automated predictive analytics, one-click analysis, intelligent information discovery, streamlined analysis, sophisticated analytics available, self-service dashboards.
Sisense
The user-friendly interface gives non-techies a trouble-free operation. It performs an ad-hoc high-volume data analysis and allows the collection of information from all of your sources into a single, affordable repository, making it a single platform that manages the entire workforce of Business Intelligence.
Tableau
Tableau lets you view and understands your data in just a few clicks by combining data from multiple sources. This allows you to generate interactive and flexible dashboards using custom filters and their drag-and-drop features.
EXPERTSMINDS.COM ACCEPTS INSTANT AND SHORT DEADLINES ORDER FOR DATA LAKE ARCHITECTURE ASSIGNMENT - ORDER TODAY FOR EXCELLENCE!
Part 2
Data Lake Architecture
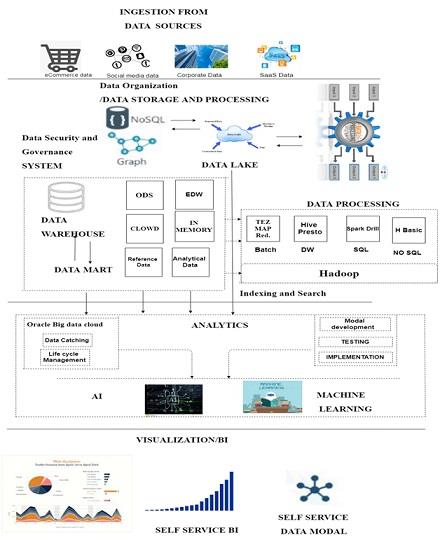
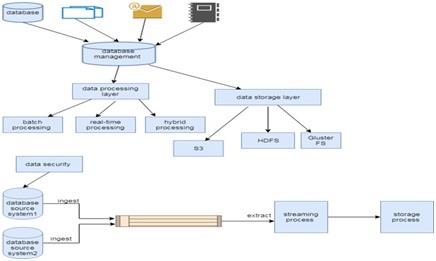
Description of the workflow diagram :
A data lake is a storage warehouse of data which can store the vast amount of raw data including structure format and unstructured data. It contains the various types of data without a specific purpose in mind that can build in multiple technologies like Hadoop, NoSQL, amazon storage service, MongoDB according to the papers called.
Data ingestion is data storage from the sources such as e-commerce data, social media data, corporate data, and SAAs data. Data organization defines the manage data from different sources and processing with the technologies NoSQL and data lake. Data security for an enterprise data lake is major priority such as encryption, network level security, access control. Security for data warehouse can access data mart and memory and memory transfer data from a mode. In Data Lake, indexing and search works only the search information for sorting data. Indexing and search used the many technologies for data search from the storage. Analytics is part of the data lake for analyzing data and used for artificial intelligence and machine language. Data visualization works on self-services and speed of data or information. In dynamic business environment, the average time between a request mode of information technology for a reports and eventually receive of a robust network working report in organization are properly designed data lake and well trained business community. It is using wide range of tools.
Data ingestion:
What is it?- it allow to connectors to get data from differents sources and strores into data lake architecture .
When it use?-Data ingestion is the method of accessing and importing data to be used or stored in a database for initial use. Ingesting anything is "taking it in or absorbing something." Data can be recorded or ingested in batches in real time.
How it works?-
• All data types includes strucured, unstrucured and semi-strucured data.
• It is used in multiple ingestion like- real time, batch -processing, one time load
Data Organization:
What it is?- In this section data recorded of various sources to data base. Data organized after the processing of data.
When it use?-In wide terms, data organization relates to the procedure by which data sets are classified and organized to make them more helpful.
How it work?-data organization stroes the data logically and discover the research of inforamtion from different types.
Data security:
what it is?- In this section. Data security relates to data protection to avoid unauthorized access to databases. Security is implemented differently by various technology platforms.
When it use?-A service like the Azure Data Lake Store uses hierarchical security based on authentication lists, while key-based safety is implemented by Azure Blob Storage. These kinds of capacities in the cloud are changing rapidly, so be sure to check frequently.
How it work?-data security works on protect data from unautorized person. It provide the data easy to implement, updatation and development for the users.
Data Indexing and search:
What it is?-Indexing in databases is a way to improve a database's efficiency by reducing disk accesses needed when processing a request.
When it use?-It is a method of information structure like hierarchy or other structure used to find and retrieve information rapidly from a database.
How it work?- it works on indexing the data and research information related search.
Analytics:
What it is?-Data analytics is a technique of data analysis of raw data or a conclusion on that data. Some of the data analytics methodologies and procedures were done automatically into mechanical processes and algorithms that work for human consumption over raw data.
When it use?- it used for focusing on plan approach and data mining.
How it work?- analytics works on machine learning and artificial intelligence.
Data visualization:
What it is?- data visualization represents the data in various form like charts, line and pie charts.
When it use?-when users wants to data in graphically form then data visulization can used for show the information in graph.
how it works?-Due to the way in which the human brain works, it is easier to visualize large volumes of complex data using graphs or diagrams than combing over spreadsheets or reports... Visualization of data can also: identify regions where attention or enhancement is needed.
ORDER NEW DATA LAKE ARCHITECTURE ASSIGNMENT & GET 100% ORIGINAL SOLUTION AND QUALITY WRITTEN CONTENTS IN WELL FORMATS AND PROPER REFERENCING.
Below are the related courses in which we offer Assignment Help Service:
- ITEC842 Enterprise Management Assignment Help
- ITEC844 Strategic Project Management Assignment Help
- ITEC830 Web Data Technologies Assignment Help
- ITEC801 Distributed Systems Assignment Help
- ITEC812 Special Topic in Information Technology Assignment Help
- ITEC810 Information Technology Project Assignment Help
- ITEC832 Enterprise Application Integration Assignment Help
- ITEC841 Information Systems Project and Risk Management Assignment Help
- ITEC800 Systems Engineering Process Assignment Help
- ITEC850 Network System Design Assignment Help
- ITEC803 Advanced Topics in Computer Networks Assignment Help