ORDER NEW COPY OF ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT AND SECURE HIGHER MARKS!
ICT110 Introduction to Data Science - University of the Sunshine Coast
Data analysis report of the health and population statistics of East Asian and Pacific countries
NEVER BE CAUGHT IN PLAGIARISM, AVAIL ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT HELP SERVICE OF EXPERTSMINDS.COM AND SAVE HIGHER MARKS!
1. Introduction
Provide an introduction to the problem. Include background material as appropriate: who cares about this problem, what impact it has, where does the data come from, what are the dimensions and structures of the data.
1.1 Authorization and Purpose
The data taken into consideration represents the initial basic information about road transport crash deaths in Australia and it was consolidated based on the reports generated by the police each month to the State and Territory road safety authorities
1.2 Limitations
Here, the study is limited to only Australian population and hence the interpretation will be valid to the population and characteristics of Australian people and cannot be used for general population
1.3 Scope
The major objective of this study is to determine the factors that influence the road death accidents. Also, we try to determine the distribution of road death accidents which helps to understand the highest frequency of death rates along with its time and speed limit
1.4 Methodology
The data was gathered in csv format and the analysis was performed using R software package. Descriptive statistics was used to understand the distribution of interval or ratio variables and frequency distribution was normally used for qualitative variables which we use to understand the shape of these variables. Independent sample t test, One way ANOVA and Chi - square test for independence was used to test the claim
EXPERTSMINDS.COM GIVES ACCOUNTABILITY OF YOUR TIME AND MONEY - AVAIL TOP RESULTS ORIGINATED ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT HELP SERVICES AT BEST RATES!
2. Data Setup
Describe how to load the data, and how the pre-processing is performed.
The data cleaning procedure was performed by the researcher or the staff who are well trained in this process. Data cleaning is a process of identifying inconsistent records that deviate far away from the normal dataset value and therefore, these values or variables needs to be removed from the dataset before performing the statistical analysis. For example, let us consider the obesity data. Here, some of the patients demographic details seems to be missing and therefore, these missing values cannot be replaced as it related to individuals personal details. Therefore, we need to replace the missing information carefully. For the questions related with likert scale ratings, we can replace the missing information either by the median or mode value. For variables, the missing information can be replaced by the average values
ENROL WITH ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT HELP AND HOMEWORK WRITING SERVICES OF EXPERTSMINDS.COM AND GET BETTER RESULTS IN ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENTS!
3 Exploratory Data analysis
Perform 2 one-variable analyses. Plot one graph for each variable. Explain the finding for each graph.
3.1 One variable analysis
3.1.1 One variable analysis 1
mydata<-read.csv("D:/Downloads/crashdata.csv",header=T,sep=",")
attach(mydata)
head(mydata)
boxplot(Speed.Limit)
The box plot for speed limit variable is given below
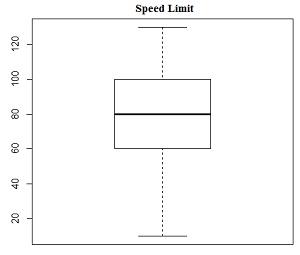
From the above box plot, we see that the distribution of speed limit follows normal distribution approximately. The middle line in the box plot called the median divides the box in equal halves, indicating that the distribution of box plot follows normal distribution
3.1.2 One variable analysis 2
The distribution of crash type is given below
plot(Crash.Type)
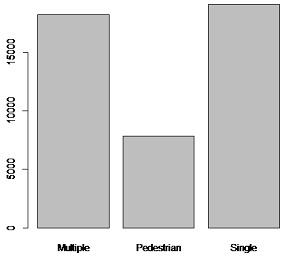
The bar chart given above shows that the maximum number of crash type is either single or multiple. Thus, majority of the crash type fall between these two categories and therefore proper preventive action should be taken to minimize these kind of fatalities
3.1.3 One variable analysis 3
The time variable is categorized into eight groups and are given below
12:00 am - 3:00 am
3:00 am - 6:00 am
6:00 am - 9:00 am
9:00 am - 12:00 pm
12:00 pm - 3:00 pm
3:00 pm - 6:00 pm
6:00 pm - 9:00 pm
9:00 pm - 12:00 am
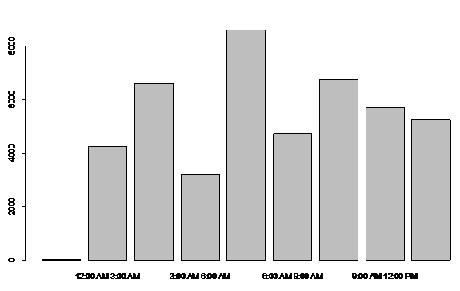
From the above bar chart, we see that the maximum number of accident occurred during the time of 9 AM and 12 PM which shows a clear indicating that the fatalities occurs during the peak hours of the day
3.2 Two-variable analysis
3.2.1 Two-variable analysis 1
The association between crash type and time is assess using clustered bar chart
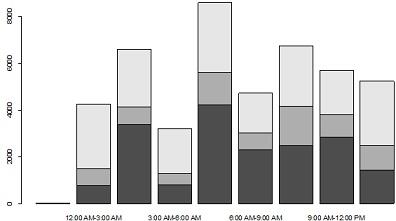
3.2.2 Two-variable analysis 2
counts<- table(Crash.Type,Time3hours)
>barplot(counts)
>counts<- table(Crash.Type,Christmas.Period)
>barplot(counts)
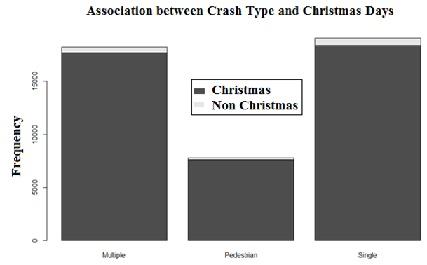
Here, we see that most of the crash type fatalities are happening on non-Christmas days
24/7 AVAILABILITY OF TRUSTED ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT WRITERS! ORDER ASSIGNMENTS FOR BETTER RESULTS!
4 Advanced analysis
Briefly explain the concept of clustering and k-means.
Perform 1 clustering analysis to group years according to a selected cause.
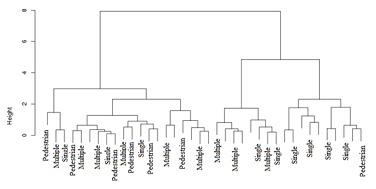
4.1 Clustering
The k-means clustering is a statistical technique used in cluster analysis to partition n observations in to k clusters where each observations is said to be belong to the nearest mean clusters. On the other hand, hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Therefore, to partitioning n observations in K non-overlapping clusters such that there is at least one observation in each cluster can be done in nCk ways
4.1.1 Brief explanation of k-means and clustering
4.2 Linear Regression
Briefly explain the concept of linear regression.
Perform 2 linear regression analysis. Plot the learned models.
4.2.1 Brief definition of Linear Regression
Simple linear regression analysis was performed to predict speed limit using bus accident as independent variable
|
SUMMARY OUTPUT
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Regression Statistics
|
|
|
|
|
|
|
Multiple R
|
0.071177
|
|
|
|
|
|
|
R Square
|
0.005066
|
|
|
|
|
|
|
Adjusted R Square
|
0.005043
|
|
|
|
|
|
|
Standard Error
|
20.5181
|
|
|
|
|
|
|
Observations
|
43852
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ANOVA
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Significance F
|
|
|
Regression
|
1
|
93999.58
|
93999.58
|
223.281
|
2.32E-50
|
|
|
Residual
|
43850
|
18460515
|
420.9924
|
|
|
|
|
Total
|
43851
|
18554514
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Coefficients
|
Standard Error
|
t Stat
|
P-value
|
Lower 95%
|
Upper 95%
|
|
Intercept
|
82.33147
|
0.098823
|
833.1203
|
0
|
82.13777
|
82.52516
|
|
Bus
Involvement
|
-11.3368
|
0.758694
|
-14.9426
|
2.32E-50
|
-12.8239
|
-9.84979
|
The coefficient of determination is 0.0056, indicating that 0.56% of the variation in speed limit is explained by the regression model, while the remaining left unexplained.
The regression equation is
Speed limit = 82.33 - 11.34 * Bus Involvement
4.2.1 Linear Regression Model 2
Simple linear regression analysis was performed to predict speed limit using crash type as independent variables
|
SUMMARY OUTPUT
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Regression Statistics
|
|
|
|
|
|
|
Multiple R
|
0.333198
|
|
|
|
|
|
|
R Square
|
0.111021
|
|
|
|
|
|
|
Adjusted R Square
|
0.11098
|
|
|
|
|
|
|
Standard Error
|
19.39418
|
|
|
|
|
|
|
Observations
|
43861
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ANOVA
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Significance F
|
|
|
Regression
|
2
|
2060177
|
1030088
|
2738.619
|
0
|
|
|
Residual
|
43858
|
16496494
|
376.1342
|
|
|
|
|
Total
|
43860
|
18556670
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Coefficients
|
Standard Error
|
t Stat
|
P-value
|
Lower 95%
|
Upper 95%
|
|
Intercept
|
87.23772
|
0.143139
|
609.4605
|
0
|
86.95716
|
87.51827
|
|
Pedestrian
|
-19.4699
|
0.264562
|
-73.5928
|
0
|
-19.9884
|
-18.9513
|
|
Multiple
|
-4.22375
|
0.203706
|
-20.7346
|
4.84E-95
|
-4.62302
|
-3.82449
|
The coefficient of determination is 0.111, indicating that 11.1% of the variation in speed limit is explained by the regression model, while the remaining left unexplained.
The regression equation is
Speed limit = 87.238 - 19.47 * Pedestrian - 4.22 * Multiple
5 Conclusion
The data taken into consideration represents the initial basic information about road transport crash deaths in Australia and it was consolidated based on the reports generated by the police each month to the State and Territory road safety authorities. Here, we see that the majority of the crash type fall between these two categories and therefore proper preventive action should be taken to minimize these kind of fatalities. Also, the maximum number of accident occurred during the time of 9 AM and 12 PM which shows a clear indicating that the fatalities occurs during the peak hours of the day
6 Reflection
The major objective of this study is to determine the factors that influence the road death accidents. Also, we try to determine the distribution of road death accidents which helps to understand the highest frequency of death rates along with its time and speed limit. Here, the study is limited to only Australian population and hence the interpretation will be valid to the population and characteristics of Australian people and cannot be used for general population.
GET ASSURED A++ GRADE IN EACH ICT110 INTRODUCTION TO DATA SCIENCE ASSIGNMENT ORDER - ORDER FOR ORIGINALLY WRITTEN SOLUTIONS!
Access our University of the Sunshine Coast Assignment Help Services for its related courses such as:-
- ICT701 Relational Database Systems Assignment Help
- ICT112 Creative Problem Solving with Programming assignment help
- ICT705 Data and System Integration Assignment Help
- ICT115 Introduction to Systems Design assignment help
- ICT702 Data Wrangling Assignment Help
- ICT120 Introduction to Computer Networks assignment help
- ICT703 Network Technology and Management Assignment Help
- ICT351 ICT Professional Practice assignment help
- ICT707 Data Science Practice Assignment Help