ENROL WITH DATA MINING TECHNIQUES ASSIGNMENT HELP AND HOMEWORK WRITING SERVICES OF EXPERTSMINDS.COM AND GET BETTER RESULTS IN DATA MINING TECHNIQUES ASSIGNMENTS!
ITECH7407- Real Time Analytic - Data Analytics Assignment - Federation University, Australia
This is a business analytics project aimed at generating innovative analytics solutions for a Company. The objective is to analyze the given datasets from a relevant firm's perspective in terms of implications and strategies which the chosen company could adopt to improve its functions, resources and processes efficiently and effectively.
Task 1- Background information - Write a description of the selected dataset and project, and its importance for your chosen company. Information must be appropriately referenced.
Introduction
In this report, we have selected the data set for the win prediction for the NFL (The National Football League) games since the 1920 to 2018 using the Five Thirty Eight's Elo win probabilities. Elo rates an algorithm that predicts teams or players on the basis of head-to-head results and has used it over the years to rate rivals in basketball, baseball, NFL, tennis and other sports. In the data set we have been given the elo1 and the elo2 which are the winning algorithm for the team 1. With the help of the elo1 and the elo2 we will calculate the eloprobability which shows the close relationship with the winning team.
22BET Betting Company was started by gambling enthusiasts. Our data set analysis will be very useful for the company as people place bet on NFL season heavily. 22BET Betting Company wants to make a more accurate guess about the winning and losing of the company so that it can make a good guess in favor of the winning team and give maximum return to the customer as well as maximize its profit.
The company knows what optimal provider should be more like from a client's perspective and they aspire to do everything for their clients. At 22BET user will find all that conventional gambling has to offer, the widest possible option of markets on any athletics as well as useful payouts, fast overdrafts, a distinctive compensation system for existing customers and more.
22BET acknowledges a wide range of bets - singles, collectors, frameworks, chains and the sky is the limit from there. By and large there are more than 30 kinds of business sectors for each occasion - from the standard bets on the victor and sums to extra incapacitate bets, wagers on the quantity of cards in a match, occasions to occur in a game, singular player details and considerably more.
It is an online betting company, where users can put their money through online transaction mode and be able to bet on numerous sports including the NFL (national football league). 22 Bets give as soon as possible a comprehensive list of deposit techniques and process repayments. In addition, all payments are totally safe and various cryptography and encryption are used to protect the transactions.
In 2014, it has been created NFL Elo ratings to predict the result of each game. Essentially, Elo gives a super rating to each team and the average NFL rating is about 1500. Each rating are used to predict the probabilities of winning for each play. The algorithm is based on the difference in the quality of two teams involved , what are the manipulation done in the starting quarter back by the teams, distance travelled by the teams and the location of the matchup and the resting days of each teams before participating a game.
After the match, in regards to how unexpected the result was and the winning margin, the rating of each team shifts depending on the result. For each match, this procedure is repeated, from the September kickoff to the Super Bowl. The probability of winning team A from two teams (A and B) with the defined ELO rating is calculated as
For any game between two teams (A and B) with certain pregame Elo ratings, the odds of Team A winning are:
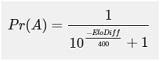
ELODIFF is the rating of Team A difference in the rating of Team B, plus or minus the difference in multiple modifications.
At QB, the play's most significant situation, we introduced a way to compensate for modifications in quality and staff. This is how this operates:
Based on their latest results, both teams and personal quarterbacks have sliding scores. Rates are determined by "value," a comparison between ESPN's Total QBR yards above substitution and fundamental game log figures such as rushing match statistics, adapted for the reliability of opposition players (defenders). Before each match, the quarterback Elo modification is implemented by adding the starting QB rolling VALUE score to the rolling score of the team and compounding by 3.3.
24/7 AVAILABILITY OF TRUSTED DATA MINING TECHNIQUES ASSIGNMENT WRITERS! ORDER ASSIGNMENTS FOR BETTER RESULTS!
Task 2 - Perform Data Mining on data view - Upload the selected dataset on SAP Predictive Analysis. For your dataset, perform the relevant data analysis tasks on data uploaded using data mining techniques such as classification/association/time series/clustering and identify the BI reporting solution and/or dashboards you need to develop for the operational manager of the chosen company.
Task 3 - Research - Justify why you chose those BI reporting solution/dashboards/data mining technique in Task 3 and why those data sets attributes are present and laid out in the fashion you proposed (feel free to include all other relevant justifications).
Description
Data mining techniques:
In order to produce updated information, data mining is the method of looking at big data centers. Logically, we can think that "mining" data relates to extracting new information, but this is not the case; alternatively, data mining is about drawing conclusions, trends and new knowledge from the data that we have already retrieved. Experts in data mining have devoted their professions to clearer understanding how to handle and make conclusions from large quantities of data, focusing on methods and innovations from the junction of directory handling, stats and algorithms. We will discuss some of those methods here and analyze the outcomes on our data set.
1. Classification
Classification is a feature of data mining which assigns objects to target subgroups or classes in a set. The classification objective is to anticipate the target class correctly in the information for each situation. A classification process starts with a collection of information that knows the class tasks. In our data set there is twelve attributes namely date, season, neutral, playoff, team1, team2, elo1, elo2, elo_prob1, score1, score2 and result1.
Classifications are discreet and do not mean order. Continuous, floating-point values would show a target that is mathematical and unambiguous. A numerical target predictive model utilizes a regression algorithm, not an algorithm for classification. Binary classification is the easiest form of classification problem. The target attribute has only two possible values in binary classification. A classification system discovers connections between the predictor attributes and the target attributes in the design build (training) phase.
In order to find connections, distinct classification algorithms use distinct methods. These connections are summed up in a model that can then be implemented to another set of data where class assignments are uncertain. Classification models are evaluated using a set of test information to compare the expected values with known target values. Usually, the historical information for a project of classification is split into two information sets: one for model construction; the other for model monitoring. Classification results in class quantization and likelihoods for each case. The classification has many implications in customer clustering, company modeling, advertising, loan analysis, and clinical and medicinal reaction modeling.
Graph:

GET ASSURED A++ GRADE IN EACH DATA MINING TECHNIQUES ASSIGNMENT ORDER - ORDER FOR ORIGINALLY WRITTEN SOLUTIONS!
2. Association
Associations rules are if-then assertions that assist demonstrate the likelihood of interactions in different kinds of databases between information things within big information sets. Association data mining has a number of uses and is commonly used in relational data to assist find sales associations. Association is one of the best-known techniques of information mining. In connection, a pattern is found in the same transaction based on a connection of a specific object to other products.
The rule of association is usually applied to the big size of information. In market basket analysis, the association method is used to define which products are commonly purchased by clients together. Based on this information, companies can have the appropriate advertising campaign to offer more goods to create more gain. Classification focuses on the methods of information mining that are used for such reasons.
Being generic as it must attempt to incorporate as many algorithms of learning as necessary. In the meantime, the system must be able to generate a decision mechanism through meta-learning and thus be able to determine the most appropriate algorithm for each data mining task, depending on the basic features of the data set, user requirements and background knowledge gained from previous data mining sessions.
Graph:
3. Clustering
Clustering is a method of information mining used to position the components of information in their similar groups. Clustering is the method by which the information (or items) is partitioned in the same class, the information in one class is much more identical to one another than the data in another. The process of sub class segmenting information items is called as a cluster. A cluster comprises of a large inter-similarity information item with low intra-similarity. Cluster quality is dependent on the technique used. Clustering is also called data segmentation, as it divides big information sets into factions as per their resemblance. This data mining technique is able to represent the information by fewer clusters usually loses some good information, but simplification is achieved. By its clusters, it designs information. Data modeling brings clustering rooted in mathematics, stats, and numerical analysis in a historical view.
From the view of machine learning, clusters match concealed patterns, cluster analysis is unmonitored learning, and the ensuing scheme reflects an information notion. In data mining apps such as statistical data exploring, data recovery and content mining, temporal database apps, web research, CRM, advertising, clinical diagnostics, bioinformatics, and many others, clustering plays an exceptional role from a pragmatic view.
In several areas such as statistics, image processing, and artificial intelligence, clustering is the topic of active studies. This study concentrates on information mining clustering. Data mining adds to the clustering of very big data sets problems with very many distinct kinds of characteristics. This makes the appropriate clustering algorithms subject to special computational demands. Recently, a range of algorithms have appeared that fulfill these demands and have been implemented effectively to real-life data mining issues. They are the topic of an investigation.

NO PLAGIARISM POLICY - ORDER NEW DATA MINING TECHNIQUES ASSIGNMENT & GET WELL WRITTEN SOLUTIONS DOCUMENTS WITH FREE TURNTIN REPORT!
4. Regression
Regression is a data mining method used, given a specific dataset, to forecast a variety of numerical values also called constant values. For company and advertising planning, economic numerical modeling, economic modeling and trend analysis, correlation is used across various sectors. Regression analysis is a computational modeling method that examines the connection between a dependent (goal) and an autonomous (s) (predictor) parameter.
This method is used to anticipate, model data set and find the connection between the variables causal impact. Analysis of regression is a significant instrument for data modeling and assessment. Here, we fit a curve/line to the datasets in such a way as to minimize the differences between the curve or line distances of data points. One of the most commonly recognized modeling techniques is liner regression.
Usually, linear regression is one of the first techniques individuals choose while learning statistical modeling. The dependent variable is constant in this technique, the independentvariable(s) may be continuous or discrete, and the existence of the line of regression is linear. Linear Regression defines a connection between dependent variable (Y) and one or more autonomous variables (X) using a line of best fit directly, also referred as the line of regression.
Logistic regression is used to determine the likelihood of failure of case, success and event. If the dependent variable is binary (0/1, True / False, Yes / No) in nature, we should use logistic regression. Here the value of Y is between 0 and 1 and can be portrayed by an equation.
Dashboard
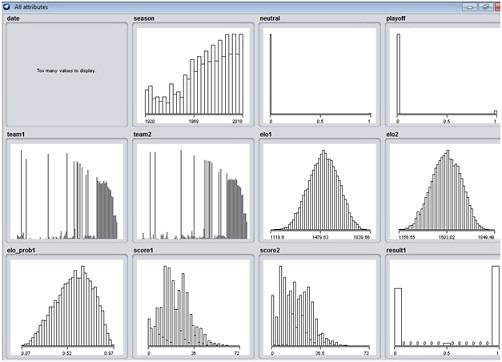
Task 4 - Recommendations for CEO - The CEO of the chosen company would like to improve their operations. Based on your BI analysis and the insights gained from your "Dataset" in the lights of analysis performed in previous tasks, make some logical recommendations to the CEO, and justify why/how your proposal could assist in achieving operational/strategic objectives with the help of appropriate references from peer-reviewed sources.
Recommendation to the CEO: This business intelligence analysis will help the 22 bet company to improve its services. It will be able to make a good guess about the winning team and accordingly adjust the betting rules to maximize its profit as well as customer satisfaction and belief. 22 Bets give fast membership, extensive prize plans and VIP bonuses, frequent award packages and a unique Bet Point monetary that user can use to purchase mementos and rewards from its Fan Store.
22Bet seeks to be a betting firm in which punters feel involved and betting is easy. With our outstanding customer-oriented service, we have gathered all the finest characteristics in one location and finished them off.22BET Sportsbook should give more than 1,000 activities every day, such as other sports. Consumers should be prepared to bet on every game, from football, tennis, ice hockey to squash, tennis, boxing and Formula 1. Moreover, in the Exceptional Bets segment, he will be able to discover a whole number of extraordinary sectors, covering politics, international news and stars.
ENDLESS SUPPORT IN DATA MINING TECHNIQUES ASSIGNMENTS WRITING SERVICES - YOU GET REVISED OR MODIFIED WORK TILL YOU ARE SATISFIED WITH OUR DATA MINING TECHNIQUES ASSIGNMENT HELP SERVICES!
Task 5 - Cover letter - Write a cover letter to the CEO of the chosen firm with the important data insights and recommendations to achieve operational/strategic objectives.
Cover letter: Dear Chairman Mr. abc
I am writing this letter on behalf of the business intelligence analysis that I have performed on the NFL (National Football League). I've considered two sources to set the original scores of teams that will be performing in a season. Each current squad holds its Elo rating from the end of that season at the beginning of each season, except that one-third of the manner back to an average of 1505 is reversed.
This is our way to hedge the wheel of free agents, free agency, exchanges and modifications in training for the offseason. We don't have a way to adjust for the real offseason movements of a team at the moment, apart from modifications at quarterback, but the next best thing is a heavy dose of regression to the mean, as the NFL has built-in systems such as the salary cap that encourage parity, drag poor teams upwards and knock excellent ones down a pair or two.
We also use Vegas win numbers for matches since 1990 to assist set Elo pre-season scores, turning to an Elo scale over-under anticipated wins. This addition to the model helped considerably enhance back testing predictive precision by slightly more than half the enhancement that QB modification did. This is partially why we blend the rolling score of the predicted starting QB into the QB pre-season rating squad. These two considerations are merged, given one-third to degenerated Elo and two-thirds to Vegas-wins Elo. This mix is what shapes the Elo pre-season ranking of a squad.
Note that when I stated last year's end-of-season scores, I mentioned "current" teams. Teams for growth have their own set of guidelines. We assign a rating of 1300 to freshly established clubs in the modern age. That is the Elo level at which the NFL expansion teams have been playing since the 1970 AFL merger. I also allotted that range in 1960 to new AFL teams, allowing the scores to be played from ground up as the AFL functioned in connection with the NFL. When the team members of the AFL fused into the NFL, they maintained their ratings while playing independently.
These techniques will help you to predict the each game more effectively with minimum error. We recommend you to use this elo method to all other sports so you can maximize your profit.
Your respectfully
xyz
Conclusion
We also have a distinct dashboard in combination with our interactive Elo, demonstrating how the Elo rating of each team has increased or dropped throughout history. These graphs will assist you monitor when your team, along with their ebbs and performance flows over time, was at its best or worst. When appropriate, the information in the graphs goes back to 1920 and is modified with each present season match.The historical visual scores will vary from those observed in our interactive current-season forecast since our QB modifications are not included in the historical ratings.
As long-time FiveThirtyEight football contributors will remember, the Elo rating is our pet measurement for assessing the level of skill of a squad at any particular time. Elo was hardly the only energy rating in city, but we like it as it's a fairly straightforward algorithm with an exquisite, continuously configurable system that makes the most out of the data it gets.
However, are football and other sporting events so distinct? The Elo equation of each sport is comparable to the Elo rating ranges. The study also indicates that individual football matches transmit approximately the same quantity of data about the relative performance of the various teams playing. The only true difference is that the playoffs of the NBA are more than five times as long as it is best-of-seven for the NFL and its regular season instead of one-and-done, so luck tends to be much less of a component. It's why the top teams in the NFL generally have a winning total near what Elo would forecast if they worked more matches against the same timetable.
HELPING STUDENTS TO WRITE QUALITY DATA MINING TECHNIQUES ASSIGNMENT AT LOW COST!
Avail the best Federation University, Australia Assignment Help for below mentioned units and courses:-
- ITECH7400 - IT Service Management And Professional Culture Assignment Help
- ITECH7401 - Leadership in IT Project Management Assignment Help
- ITECH7403 - Project Assignment Help
- ITECH7406 - Business Intelligence and Data Warehousing Assignment Help
- ITECH7408 - Social Media Strategy & Management Assignment Help
- ITECH7409 - Software Testing Assignment Help
- ITECH7413 - Supply Chain Operations and Management Assignment Help
- ITECH7415 - Masters Project Assignment Help